Robots.txt
Vad är Robots.txt?
För att hjälpa Google att läsa igenom din hemsida, crawla som det ibland kallas, kan man använda sig av en robots.txt fil. Det är kort och gott en textfil där man listar det som Google ska läsa igenom. Man kan då välja vilka sidor som man vill att Google ska söka igenom samt vilka som inte ska crawlas.
Sökmotorer förväntar sig att man ska ha en robots.txt fil och det är den första filen de kollar efter vid en crawl. Genom att ha en Robots.txt på plats kan du ge instruktioner till sökmotorn, se till att den hittar din sitemap.xml mm.
Exempel
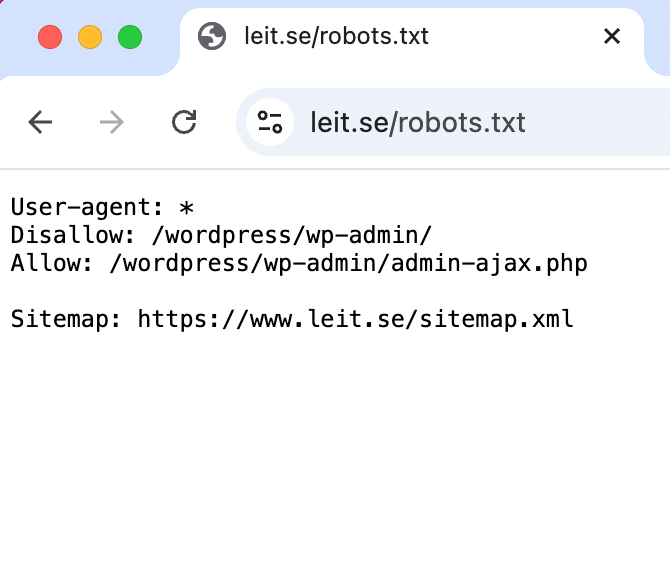
Som man ser på bilden har Leit bett Google att inte läsa igenom våra admin sidor på WordPress genom att lägga in den undersidan bakom Disallow:, där finns helt enkelt ingen information som är relevant för sökmotorer.
Vi länkar till sitemap.xml så att denna ska kunna användas av sökmotorn för att förstå webbplatsens struktur och hitta sidor som ev. inte länkas på webbplatsen.
.png?rect=4,4,666,572&q=95&fit=clip&auto=format&w=1919)
